
Elements of Programming: Fundamental Data Structures
Data Structures underlie everything we do in computer science: understanding them is critical to writing rigorous software and effective algorithms.


There are two general ways of looking at data structures: concept and implementation. Ideally, they should serve you the sense in selecting an effective data structure for a given problem. Fundamental data structures manifest themselves naturally in most situations. The problem usually demands a certain data structure, while others could be represented in different ways. An effective data structure should simplify the problem. But that is only half of the story since a data structure must also ensure computational efficiency. We can simplify the problem by conceptually looking for an apt data structure while performance benefits are obtained by looking into the implementation.
Now that we are familiar with the essence of looking at the two broad lenses in selecting a data structure, I should formally introduce you to the characters. We can view data structures from abstraction — that we shall call from hereon then as Abstract Data Type — and implementation.
An Abstract Data Types (ADT) ought to describe a set of functionalities in a given data structure — they are written in a declarative manner. It is close to an algebraic structure in mathematics that outlines the rules and operations in a particular context [1]. The inspirations from mathematics are established within a class that contains a collection of values, and behaviors that support the operations that we can do within a structure. Such an abstract model hides the implementation logic. ADT is language-agnostic as it only describes the prototype of a data structure.
List:
- add -> adds an element on the list
- remove -> removes an element on the list
- sort -> sort the list in order
- search -> search a value on the list. If value is found, return true.
- display -> display list traversal
In programming a data structure with an abstract model (ADT), a good practice is to establish loose coupling between modules that contain the ADT and the implementation specifics. The purpose is to maintain a conceptual map between programming logic and functionalities which improves the maintainability of our system.
Below is an example of implementing an ADT inside a language which in this case is C++ because the Standard Template Library (STL) is deemed mature and state of the art, it is a good reference for reading a good piece of software. However, due to its nuances and technical sophistication, we will only base our discussion on one of the core concepts of STL: containers.
Keeping this in a separate module improves maintainability and clarifies the intention of the developer before they implement the logic specific to that functionality. Do not worry about the new word singly-linked list because we would not talk about that here. For now, focus on how we wrote our ADT for describing the operations of the data structure — which in this case is a List.
# pragma once
// ADT of singly-linked list
class List{
private:
struct Node{
int data;
Node *next;
};
Node *head;
public:
explicit List();
~List();
void add(Node _node);
void remove(Node _node);
void sort();
void display();
void clear();
bool is_empty();
bool is_element(Node _node);
};
Meanwhile, the implementation specifics contain the quirks and tricks that ensure the operations ascribed in the ADT. From this perspective, it is important to know the quirks of your language to know the techniques that ensure safety and efficiency, such as referencing and memory management in languages like C/C++. For this matter, implementing the concepts defined in ADT closely works with the language; the programmer must be technically adept in the language.
In practice, these two lenses work together by establishing clarity first, then specifications.
Fundamental Data Structures

Much like the abstract and practical resemblance of Euclidean geometry to the world, ADT and its Implementation correspond in a manner where the former is purely ideal while the latter is closer with actuality.
For this section, we briefly introduce the fundamental data structures and cite some of their use cases. We shall be introduced to the following data structures.
- List
- Deque
- Tree
- Set
- Map
- Graph
Before we delve in a little further, we should keep in mind the Base functionalities of our data structures. The baseline for each structure has to support the following operations: it should be able to search an item, sort, insert, update, and delete items.
- Search − Algorithm to find an item in a data structure.
- Sort − Algorithm to organize items in a certain order.
- Insert − Algorithm to insert items in a data structure.
- Update − Algorithm to update an existing item in a data structure.
- Delete − Algorithm to remove an existing item from a data structure.
template<typename T>
class Base{
public:
Base();
virtual ~Base();
virtual void search(const T& _element) = 0;
virtual void sort() = 0;
virtual void insert(const T& _element) = 0;
virtual void update() = 0;
virtual void delete(const T& _element) = 0;
};
List
The list is an abstract data type that represents a countable number of ordered values, where the same value may occur more than once. Lists can be ordered linearly or non-linearly. Non-linear lists can be implemented in a form of a Tree, Graph, or a Map. However, we distinguished them in their respective categories for they, themselves, have their own nuances. List, in this context, pertains to a linear list family.
A list data structure is useful when the notion of order is obtained, a value is allowed to have duplicates, and whenever we would like to do sorting and searching with our data set. The List ADT is implemented in the class of Sequence containers in C++ STL. It comprises the following: array, vector, deque, forwad_list, and list.
Conceptually, all other data structures can be implemented with lists [2], however, we want to categorize them for the sorts of structures they represent, which is useful for problems we encounter.
This is related to how algorithms are categorized which I laid out here:
A common structure when we talk about a list is called linked-list (implemented in STL as a list). It is applied in many use-cases such as deriving other structures, the links you visit in a web browser, or music playlists.

Deque
Deque is a combination of queue and stack since the difference between these data structures is their ordering whereas the queue maintains a FIFO order, the stack keeps a LIFO order. Thus, deque support FIFO and LIFO ordering of a list.
FIFO means first-in, first-out ordering. The most common example would be to think of waiting in line in supermarkets. Sometimes we call this a queue where the policy established is first-come, first-served.

LIFO, on the other hand, stands for last-in, first-out ordering. Think of removing a book from a pile of books. You would have to remove the top book, iteratively until you found the book you want to read.

Queues are used for maintaining a LIFO order of precedence in processing requests. A great example would be scheduling systems: the processing is done on a first-come, first-serve basis. CPU scheduling systems exploit the LIFO property of the queue [3].
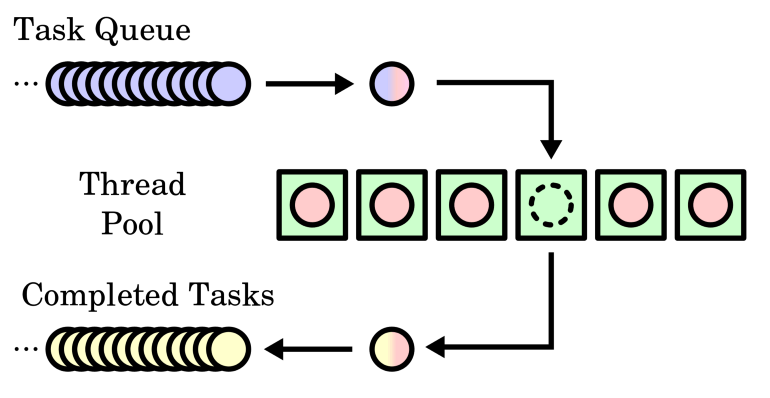
A sample thread pool (green boxes) with a queue (FIFO) of waiting for tasks (blue) and a queue of completed tasks (yellow).
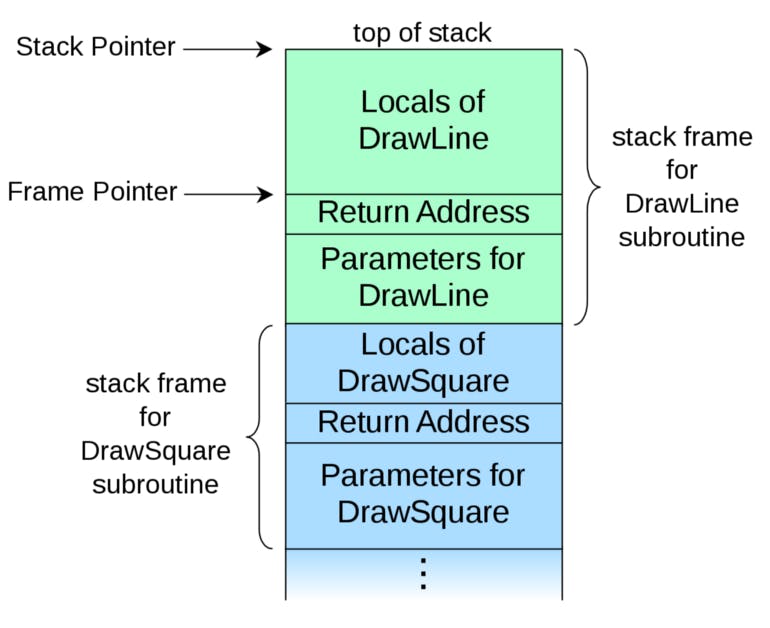
The common use-cases of the stack resonate within the language such as the call stack wherein stack data structure that stores information about the active subroutines of a computer program.
# pragma once
template <typename T>
class Deque: public Base<T>{
private:
int size;
T* front_reference;
T* back_reference;
public:
Deque();
~Deque();
// basic functionalities
void search(const T& _element) override;
void sort() override;
void insert(const T& _element) override;
void update() override;
void delete(const T& _element) override;
// specialized function in Deque container
void push_back(const T& _element);
void push_front(const T& _element);
void pop_back(const T& _element);
void pop_front(const T& _element);
void front();
void back();
};
Moving on to more specialized data structures since they rely on the previous data structures. This is where it gets so exciting!
Trees
A tree data structure is used to represent hierarchy or non-linear ordering. We commonly name them with what resembles a family tree. We will go over some common terminologies but keep in mind that it is not exhaustive.
- root — a root node is a starting point of a tree structure. It does not have a parent node.
- parent — a parent node is an immediate predecessor of a node.
- child — a child is a successor of a parent node
- leaf — a leaf is located at the end of the tree. It does not have any children.
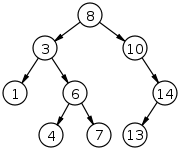
There are many versions of trees, and they can be implemented in various ways. It is important to note that although C++ STL does not have a tree container, it does implement sets as a Binary Search Tree.
A binary search tree (BST) is a particular type of tree that maintains a property of allowing only two children per parent node where the left child is always less than the parent while the right child is always greater than the parent [4].
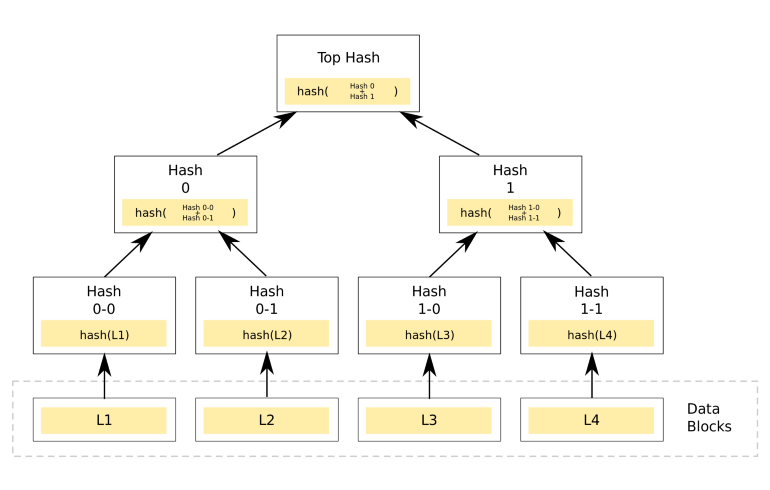
Another kind of tree that is widely used in cryptography is known as the Merkle Tree in which every leaf node is labeled with the cryptographic hash of a data block, and every non-leaf node is labeled with the cryptographic hash of the labels of its child nodes [5].
Compilers and interpreters [6] exploit the hierarchical structure and order of a tree. Parse trees are formal representations of a language that can be understood by computers.
Set
As we mentioned earlier, sets are implemented as trees. Sets are very useful for keeping unique elements in a given list, not to mention that they serve to be the foundation of mathematics — we know this from set theory. It follows that advanced mathematical concepts are realized within the structure of the set.
# pragma once
template <typename T>
class Set{
public:
Set();
~Set();
void display();
void insert(const T& _element);
void remove(const T& _element);
int size();
bool is_element(const T& _element);
bool is_empty();
bool is_disjoint();
bool is_subset(const Set& set);
Set union(const Set& set);
Set intersection(const Set& set);
Set complement(const Set& set);
Set difference(const Set& set);
Set symmetric_difference(const Set& set);
};
Map
A map is a key-value pair data structure, other languages like Python call them dictionaries. A key is an index that you use to call its corresponding value.
The computer scientist, Brian Kernighan, deemed them as the most useful kind of data structure. %[youtu.be/qTZJLJ3Gm6Q]
The most notable application of maps is in database systems.
# pragma once
# include <string>
template<typename T>
class Map{
public:
Map();
~Map();
void add(const std::string &key, const T& value);
void remove(const std::string &key, const T& value);
void get_value(const std::string &key);
void get_key(const T& value);
void display();
};
Graph
Finally, the broadest category of data structure is here!
A graph is a generalization of Trees. An area of mathematics and computer science is devoted to exploring the universe of graphs. Among my personal favorites is the realization of graph theory in automated theorem proving and some theoretical foundations in Physics, as found in Stephen Wolfram’s project.
Graphs are everywhere, and we can represent nearly all problems with a graph since a tree is a special case of a graph and a linked list is a special case of a tree.
Takeaways
Now that we covered the fundamental data structures and their use cases, we learned that we can represent problems in various forms of data structure. We also covered the areas of applications where such data structures are found most crucial. And we laid out the abstract model for implementing these data structures. A fun way to explore this area of computer science is to try and implement them on your own.
If you want to engage on this topic with me, I’ll be posting a series on the quirky bits of implementing these data structures in detail soon so stay tuned!
References
- Dale, Nell; Walker, Henry M. (1996). Abstract Data Types: Specifications, Implementations, and Applications. Jones & Bartlett Learning. ISBN 978–0–66940000–7.
- Stephens, R. (2019). Essential algorithms: a practical approach to computer algorithms using Python and C. John Wiley & Sons.
- GeekforGeeks (2018). Applications of Queue Data Structure. geeksforgeeks.org/applications-of-queue-dat..
- Wikipedia contributors. (2021, March 31). Binary search tree. In Wikipedia, The Free Encyclopedia. Retrieved 08:24, April 13, 2021, from en.wikipedia.org/w/index.php?title=Binary_s..
- Becker, Georg (2008–07–18). “Merkle Signature Schemes, Merkle Trees and Their Cryptanalysis” (PDF). Ruhr-Universität Bochum. p. 16.
- Nystrom, R. (2018). Crafting Interpreters. craftinginterpreters. com/[2. 8. 2020].