Data Presentation

I'm a CS student. I share anything I find helpful an interesting on my blogposts.
Because data are naturally messy, we need to re-organize them to gain meaningful insights. Transform them in a way that is appropriate for our data. We are in search of subtle features and relationships from our raw data. This calls for Data Explorations where our journey begins!
We can group our data based on their conceptual relationships and inherent structure. The structure and organization of our data form a basis for our exploratory analysis. There are two main strategies to gain insight from our data: we can either organize them in tabular form (with summary statistics) or visualize them to aid a more intuitive understanding of our data.
The sorts of data analysis methods rely on data representation just like algorithms on data structures.
Summary statistics are measurements about the frequency, shape, central tendency , deviation, and some factors of correlations that depends on the context of our approach. We visualize our data based on values by which we can represent their relationships. These are methods mainly used for Descriptive Statistics where our objective is to describe nuanced features of our data. This article will take a nudge on these concepts. Note that our focus is to understand how we can communicate our data.
Visual representation is crucial to communicate and figure out the subtleties of our data.
This article covers basic data presentation. I aim to give you a little bit of understanding of how the structure of your data should correspond with your model and visualization.
First, let us begin our discussion with a brief review on how we can categorize raw data in the wild.
Brief Review
There are two kinds of data we can collect: one is obtained in the population and the other is a sample from the population [1]
Raw data are building blocks of information that we obtained by directly gathering empirical results based on some parameters that we deem as relevant for our analysis. Based on their values, we can distinguish quantitative data to qualitative data. Therein, we can look at four lenses on operations that are permissible with our data by looking at levels of measurement.
| Type | Represents | Operations | Central trend |
| Nominal | category | count | mode |
| Ordinal | rank and order | add | median |
| Interval | entities with equal spacing | multiply | mean |
| Ratio | entities with true zero | trigonometric, exponential, etc. | geometric mean |
Note that as we go down to our table the operations from above are also valid with the operations below i.e. ratio accumulates all the operations above it.
Now we can move on with how we can represent our data.
Presenting your data
Our data may be grouped or ungrouped. Grouped data are arranged in a manner that we categorize our data based on criteria we set on our raw data might fall under, while ungrouped data are not categorized.
There are good reasons why we should or should not group our data. This is circumstantial. If we are interested to represent a category that falls in the same field, grouping our data with an equal range of intervals (or set of categories) would benefit us for our analysis. Grouped statistics provide a way of getting sound estimates and statistical measures for dealing with grouped data. Indeed, grouping our data might helps us discover essential patterns that emerge from our data concerning their categories wherein we cannot directly observe from analyzing ungrouped data. In some circumstances, this is a useful technique to minimize the effects of outliers on our models, let's leave that for another topic.
For now, our focus is to develop our understanding of representing analyses concerning grouped and ungrouped data.
Ungrouped data
Ungrouped data may be sorted in order. Sorting is the only means of organization we are allowed to do in this form of data. There are ample methods that we can apply to analyze ungrouped data. In fact, these methods are often simpler to do in practice, less structure means less restriction. And we know that introducing more restrictions can complicate our process.
Grouped data
When we cannot afford a sufficiently large sample size that is ideal for our model's space (pertains to the assumptions on the share of distribution), we can use techniques such as data binning the clustering categories of our data into groups. This helps us aid the detrimental effects of outliers on our model. In addition, grouped data also has many ways of organization which can result in richer visualization techniques. The same ideas are also extended for multidimensional statistics which are widely practiced in shallow Machine learning algorithms [3].
Quantitative data is grouped based on a range of values our class width might have, this is equally distributed for our intervals which determines the number of our classes. Qualitative data are grouped based on the number of elements that belong to a category.
General Types of Data Visualization
Charts. It is a category of graphical representation where data are represented by symbols such as bars, line, or sectors in a pie chart [4]. A chart is helpful whenever we want to visualize a table of numeric data, functions, or some kind of a categorical variable with its corresponding value.
Tables. It is for organizing the relationship of variables and data values. This may also be used for summary statistics.
- Graphs. It is usually applied to represent change over time, compare datasets, or show correlations between variables.
Infographics. It is composed of charts and diagrams put in place together to convey a story. This is intended to represent information quickly and clearly. They may also have annotations. This is particularly helpful for showcasing statistical reports and guiding the audients to point out relationships and notable details.
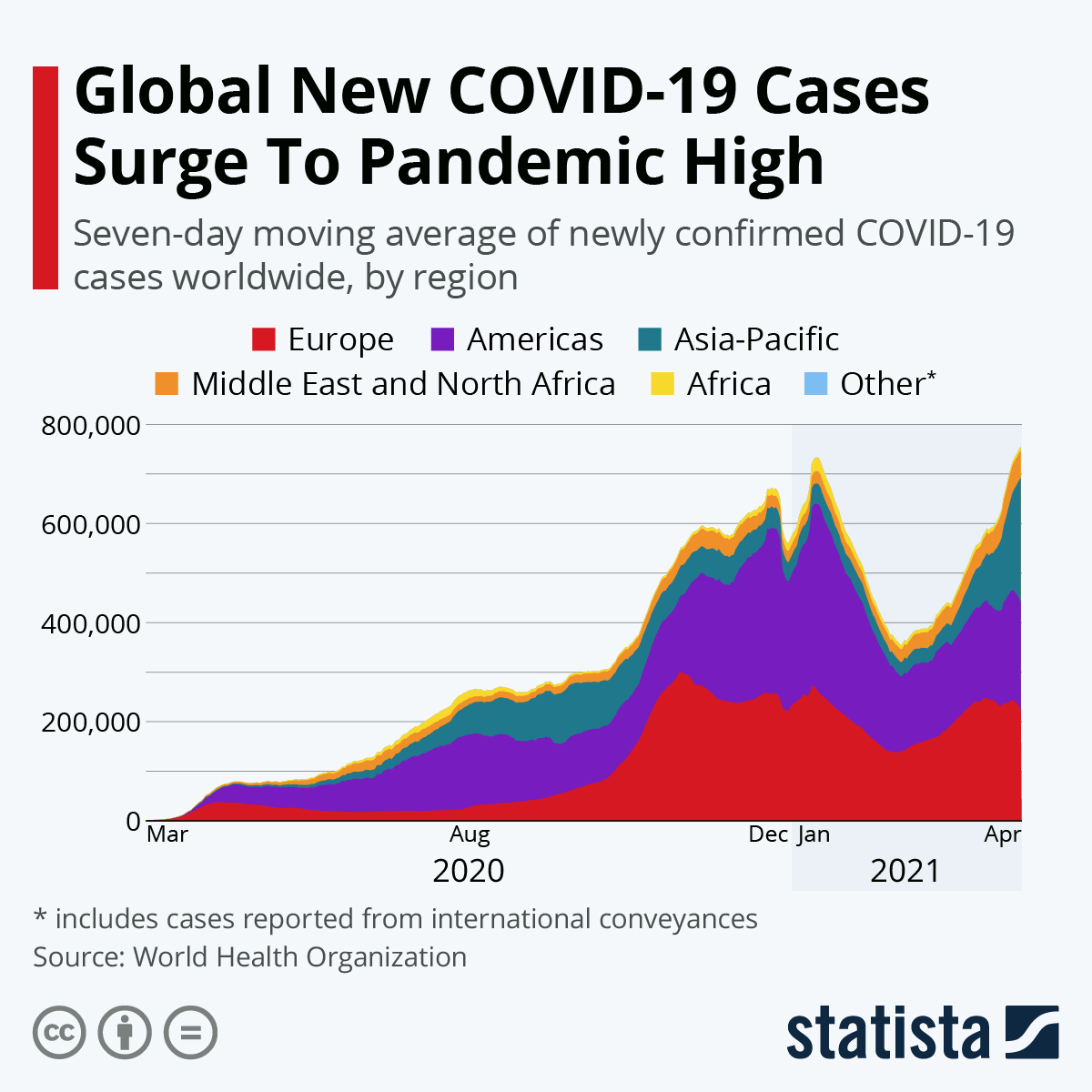
Dashboards. It is a graphical user interface (GUI) that provides insights at-a-glance. Unlike Infographics, dashboards are more objective in the sense that it gives the user the affordance of drawing their own conclusion, performing further analytics, and reconfigure visualizations in a different lens.
Takeaways
The structure of our data is the context where we begin our exploration. In doing so, the data set has to be situated with its quirks and subtleties. For choosing the right kind of visualization we must know:
- The question we are interested in answering.
- The properties of our data and their underlying structure.
- The intention on how we want to communicate our data to others.
Articles to checkout for learning more about data visualization
Main References
- Brase, C. H., & Brase, C. P. (2014). Understandable statistics. Cengage Learning.
- Bluman, A. G. (2013). Elementary statistics: A step by step approach: A brief version (No. 519.5 B585E.). McGraw-Hill.
- Zhang, A., Lipton, Z. C., Li, M., & Smola, A. J. (2020). Dive into Deep Learning.
- Cary Jensen, Loy Anderson (1992). Harvard graphics 3: the complete reference. Osborne McGraw-Hill ISBN 0-07-881749-8 p.413
- Tableau (2021). Choose the Right Chart Type for Your Data. Tableu.com. https://help.tableau.com/current/pro/desktop/en-us/what_chart_example.htm
- Our World in Data (2020). Coronavirus (COVID-19) Cases. https://ourworldindata.org/covid-cases.
- Statista (2020). New COVID-19 Cases Surge to Pandemic High. https://www.statista.com/chart/22067/daily-new-cases-by-world-region/




